


Introduction
As organizations increasingly look to harness the power of artificial intelligence (AI), one challenge consistently rises to the top: getting the right data, in the right shape, at the right time. Building an effective large language model (LLM) is not simply a matter of choosing the right model architecture or hiring the right data scientists. The real challenge, the one that consumes the most time, resources, and organizational energy, is preparing the data. Having worked in automation and data handling, I have seen this challenge repeatedly. Therefore, the key question becomes, “How can you most efficiently prepare enterprise data for LLM training?”
ConnectALL by Broadcom is a solution with many different use cases, but at its heart it exists to connect your entire ecosystem of tools, processes, and people. In this blog, I want to focus on one specific and increasingly valuable use case: Using ConnectALL to collect and prepare the data needed to power your LLM, whether through training, fine-tuning, or retrieval-based approaches, such as retrieval-augmented generation (RAG).
This is where automation becomes strategic. A well-configured value stream automation platform does not just move data; it enables AI readiness.
What is ConnectALL?
ConnectALL is an intelligent value stream automation platform developed by Broadcom, sitting within the ValueOps portfolio. At its core, it is designed to eliminate the friction that exists when organizations operate across multiple, disconnected tools, teams, and domains.
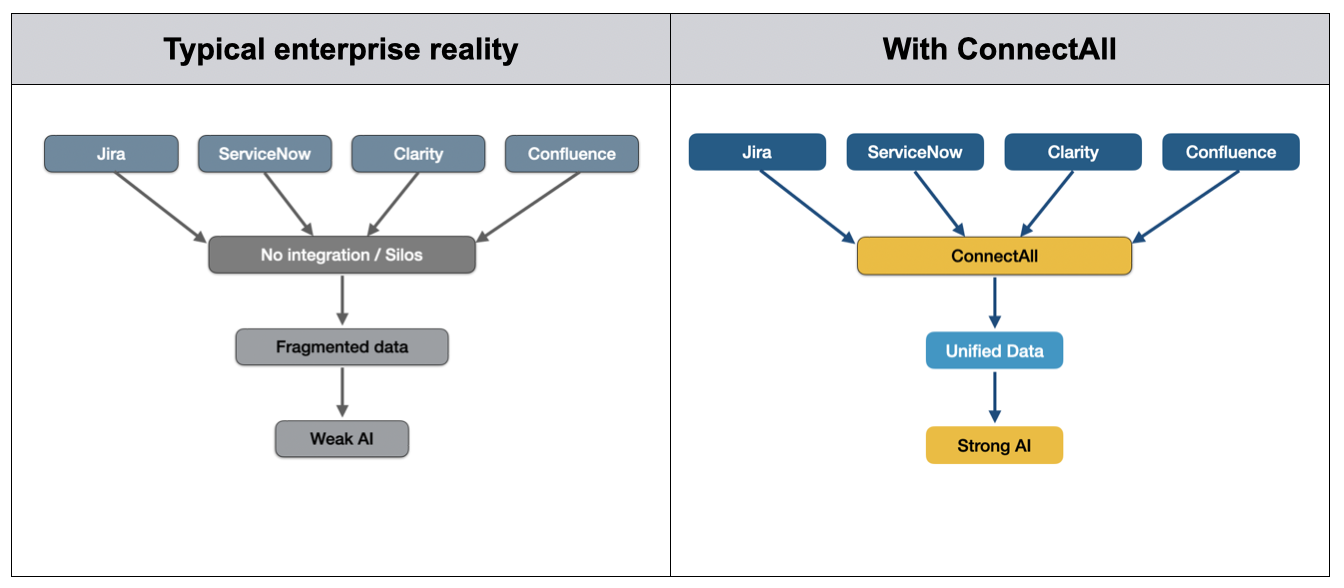
In most enterprises, work does not happen in a single system. Teams across every level of the organization use a wide range of tools. Often, these tools are used in parallel and lack seamless integrated automation between them. ConnectALL acts as the intelligent bridge between these systems, enabling an automated, bi-directional flow of data, work items, and critical context.
Rather than relying on manual data transfers, duplicate entry, or brittle custom integration, ConnectALL provides out-of-the-box connectivity across a wide range of enterprise tools. It synchronizes workflows, aligns teams, and, critically for AI use cases, consolidates fragmented data into a coherent and accessible form.
Unlike traditional extract, transform, and load (ETL) platforms, ConnectALL operates at the level of work and context, not just raw data. It maintains relationships between entities, preserves meaning across systems, and enables near real-time synchronization, all of which are essential when preparing data for modern AI architectures. (To learn more, check out a prior blog post that examines how ConnectALL helps tame the data beast.)
What does an LLM actually require from data?
Before exploring how ConnectALL helps, it is worth grounding ourselves in what LLMs actually require from a data perspective.
LLMs learn or operate based on vast quantities of text and contextual information. Whether you are training a model, fine-tuning it, or using a retrieval-based approach such as RAG, the effectiveness of the system is directly determined by the quality of the underlying data. Training embeds knowledge directly into the model, while RAG retrieves relevant information from external sources at the time of the query. In both cases, the outcome depends on having accessible, well-structured, and reliable data.
For enterprise use cases, that data must meet four key criteria:
-
Volume, delivering sufficient data to provide meaningful coverage.
-
Variety, offering representation across formats, use cases, and contexts.
-
Quality, providing clean, deduplicated, and reliable information.
-
Consistency, employing a standardized structure across all sources.
Thin, inconsistent, or fragmented datasets lead to weak outputs, regardless of how advanced the model itself may be.
The problem: Where organizations get stuck
Despite clear intent, most organizations encounter the same structural challenges when preparing data for LLM. Here are the most common obstacles:
-
Data silos. Business-critical knowledge is distributed across numerous systems, including service management platforms, agile delivery tools, CRMs, documentation repositories, and more. Each contains valuable context, but none are designed to work together. The result is a fragmented and incomplete view of organizational knowledge.
-
Inconsistent formats. Even when data can be extracted, it rarely aligns. Field structures differ, naming conventions vary, and categorization is inconsistent. Before this data can be used, it must be normalized, a process that is time-consuming and error-prone when handled manually.
-
Manual, resource-intensive processes. Without automation, data preparation becomes a project in itself. Teams spend weeks or months identifying sources, extracting data, cleaning it, and preparing it for downstream use. This delays AI initiatives and diverts skilled resources away from higher-value work.
-
Governance and compliance risks. Not all data is suitable for use in AI systems. Sensitive information, regulated data, and internal-only content must be identified, filtered, or anonymized. Without proper controls, organizations expose themselves to significant risk.
These challenges are not edge cases. They are structural characteristics of modern enterprises and the primary reason why data preparation remains the most time-consuming phase of any AI initiative.
How ConnectALL solves the problem
This is where ConnectALL moves from being an automation tool to becoming a strategic AI enabler. How does ConnectALL deliver the data that promotes AI readiness?
Aggregating enterprise data
ConnectALL ties into the systems in which knowledge already exists, from delivery tools such as Jira, to service platforms like ServiceNow, to CRMs and documentation systems. It consolidates these disparate sources into a unified data layer without requiring manual extraction.
Automating continuous data flows
Data preparation is no longer a one-off effort. ConnectALL enables continuous, automated pipelines, ensuring that datasets or retrieval layers in RAG architectures remain current as the organization evolves.
Standardizing and transforming data
Through field mapping and transformation capabilities, ConnectALL normalizes data into consistent structures. This reduces manual effort and ensures that downstream AI systems receive clean, usable input.
Enabling downstream AI architectures
Once aggregated and standardized, data can be fed into data lakes, document stores, or vector databases that support RAG-based retrieval. ConnectALL ensures that these downstream systems are built on high-quality, consistent, and trusted data.
Supporting governance and control
By centralizing data movement through a single automation layer, organizations gain visibility and control over what data is used, where it comes from, and how it is processed. This enables stronger governance and compliance.
Accelerating time to value
What previously required months of manual effort can be reduced to weeks or less. This allows organizations to move from fragmented data to AI-enabled use cases, and to do so significantly faster.
Conclusion
The promise of enterprise LLMs is compelling. These LLMs can create AI systems that understand your organization’s knowledge, processes, and language.
But the success of those systems does not depend on the model alone. It depends entirely on the quality of the data that supports it.
Whether you are training a model, implementing RAG, or combining both approaches, the challenge remains the same: You need to make enterprise data accessible, consistent, and trustworthy.
ConnectALL provides the foundation to achieve this. By connecting systems, automating data flows, and enforcing consistency and governance, it transforms data preparation from a bottleneck into a repeatable capability. (See a prior post to find out more about how ValueOps by Broadcom helps promote strong ROI from AI investments.)
The question is no longer whether you can build an LLM.
It is whether your data is ready to support one.
We are more than happy to help. Reach out to us to start a conversation about how to use ConnectAll for LLM data preparation.
Frequently asked questions
Q: How does ConnectALL differ from a traditional ETL platform when preparing AI data?
A: Unlike traditional ETL tools that focus on raw data, ConnectALL operates at the level of work and context, maintaining relationships between entities and preserving meaning across systems.
Q: What are the four primary criteria that enterprise data must meet to be effective for LLMs?
A: To ensure strong outputs, organizational data must have sufficient volume, representation across various contexts, high quality, and a standardized, consistent structure.
Q: Can ConnectALL help with the governance and compliance risks associated with AI?
A: Yes, ConnectALL provides a centralized automation layer that gives organizations visibility and control over what data is processed, helping to filter or anonymize sensitive information.
Q: Which specific AI architectures can benefit from using ConnectALL for data preparation?
A: ConnectALL supports a variety of approaches, including direct model training, fine-tuning, and retrieval-based architectures like RAG.








